Capability is becoming free. Judgment is becoming everything.
Bottom line: The cost of AI capability is collapsing toward zero, which means capability is no longer where advantage lives. The enterprises that win the next decade will not be the ones with the best models. They will be the ones with the best judgment about where to apply AI, what to refuse to automate, how to earn trust, and what to fund. That is what "AI-native" actually means — and it is a discipline, not a technology.
The thing you are paying a premium for is about to be free
Start with the uncomfortable part. The capability you are budgeting against this year — a model that can reason over your documents, draft your code, summarize your calls, answer your customers — is getting cheaper at a rate that has almost no precedent in enterprise technology. Stanford's AI Index has tracked the price of reaching a fixed level of model performance falling by a large multiple in roughly eighteen months, as cheaper models catch up to last year's frontier and inference prices compress across providers (Stanford HAI, AI Index Report 2025). At the same time, the gap between the best model and the tenth-best has narrowed to the point where open-weight systems now sit within striking distance of closed frontier models on the public leaderboards.
Hold those two facts together and the implication is hard to avoid. If the capability is getting cheaper and the providers are converging, then any advantage you build on we have the better model has a short half-life. You are renting it. So is your competitor. The model is becoming a commodity input, like bandwidth or compute before it — necessary, unremarkable, and not yours.
This is not a prediction that capability stops mattering. It is the opposite of a luxury good: it matters so much that everyone will have it. And the moment everyone has a thing, having it stops being the point.
When a capability becomes universal, possessing it stops being a strategy. Deciding what to do with it becomes the only strategy left.
The failure rates disagree with each other — and that disagreement is the real finding
Here is where most AI strategy conversations go wrong. They fixate on the failure statistics. You have seen the numbers: somewhere between forty and ninety-five percent of enterprise AI initiatives are said to fail, stall, or never reach production. Gartner has publicly projected that the majority of generative AI projects will be abandoned after proof of concept; a 2025 report from MIT's NANDA initiative found that the large majority of enterprise GenAI pilots delivered no measurable return to the profit-and-loss statement.
The honest observation is not which number is correct. It is that the numbers cannot all be measuring the same thing — and they aren't. One counts abandoned proofs of concept. Another counts pilots that deployed but produced no profit-and-loss impact. A third counts systems that never left the lab at all. The range is so wide because the denominators are different, and that tells you something more useful than any single figure: the projects are not failing at the model. If the constraint were capability, the failures would cluster at a clean technical threshold. Instead they scatter across the messy human territory after the model works — data that was never integration-ready, workflows the system never fit, experts who never trusted it, budgets that funded a launch and forgot the operating cost. The barriers that survey after survey put at the top of the list are organizational, not technical: data quality and governance, integration, risk, and talent (Deloitte and McKinsey state-of-AI surveys, 2024–2025).
Read that closely and the thesis turns. If the model is not the constraint, then capability is not the edge. The edge is everything around the capability. The edge is judgment.
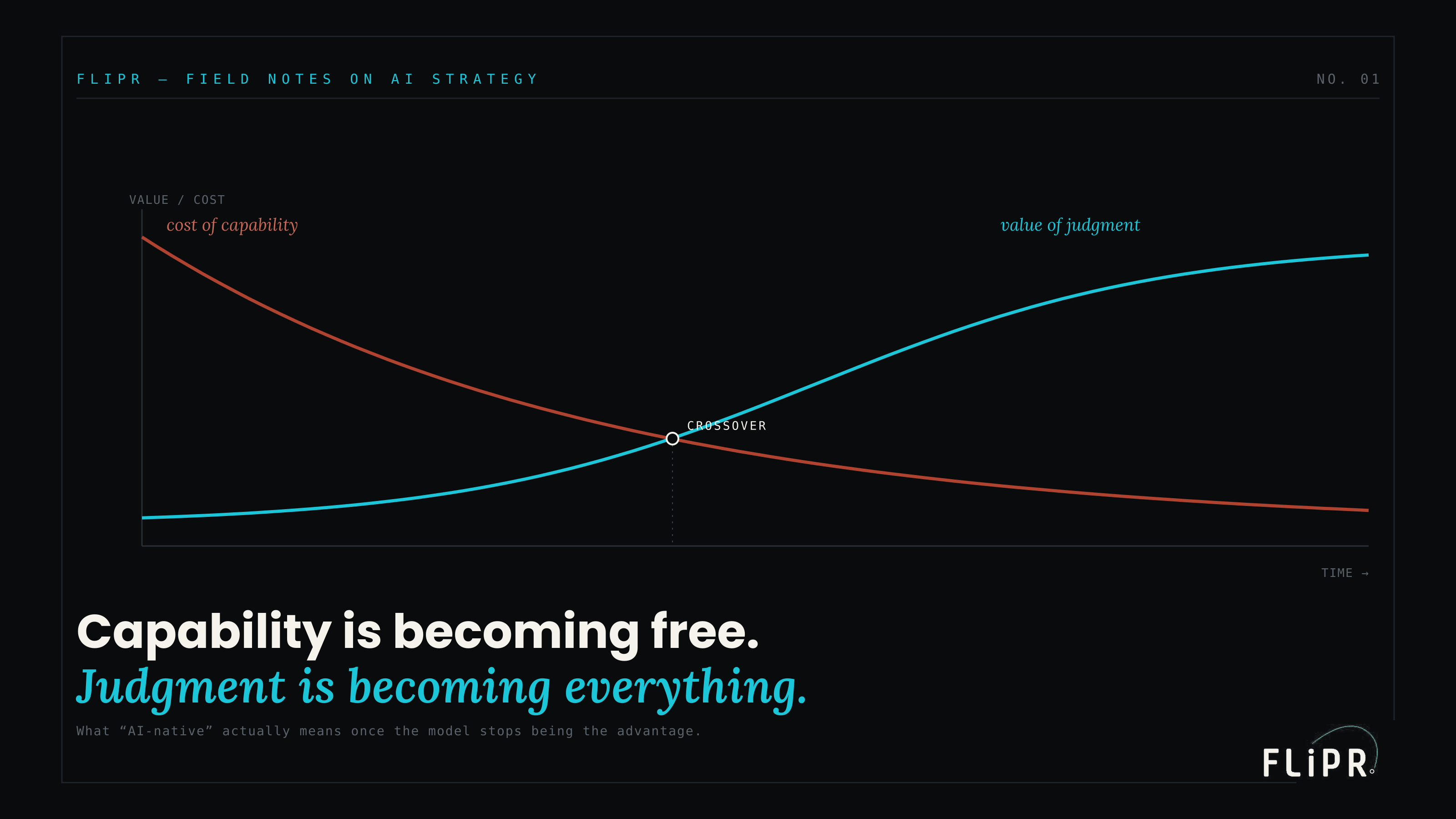
The Capability–Judgment Scissors
Picture two curves on the same axes over time.
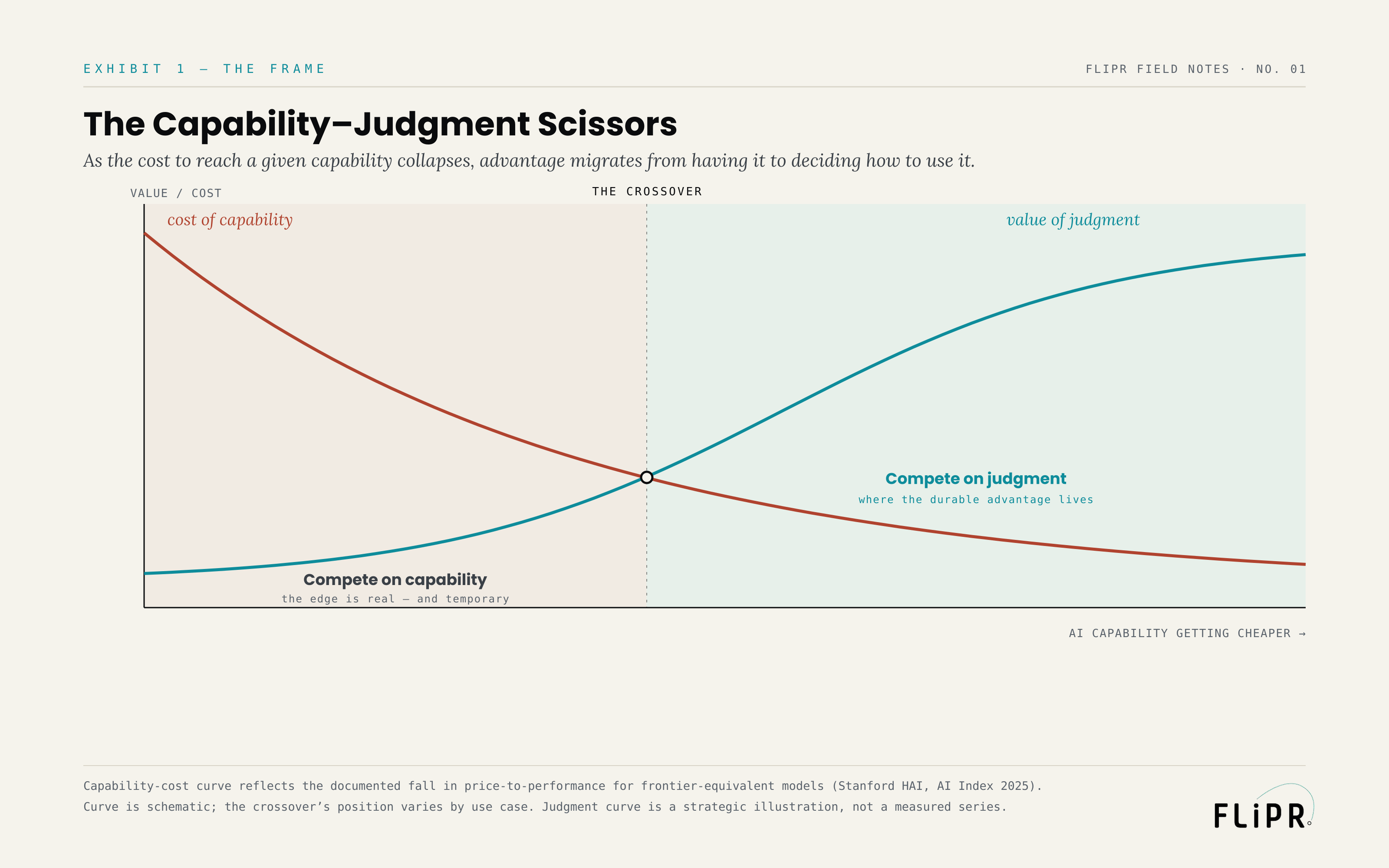 Exhibit 1. To the right of the crossover — where most enterprises now operate — the spread between winners and losers is explained by judgment, not capability.
Exhibit 1. To the right of the crossover — where most enterprises now operate — the spread between winners and losers is explained by judgment, not capability.
The first is the cost of capability. It falls — steeply, and then it keeps falling, as models commoditize. The second is the value of judgment: the worth of deciding correctly where to point the capability, how much of it to use, whether to use it at all. As capability gets cheaper and more abundant, good judgment about it becomes scarcer and more valuable, because there is simply more capability to misapply. The two curves cross.
Call it the crossover. To the left of it, capability is genuinely scarce and expensive, and having more of it than your competitor is a real — if temporary — advantage. To the right of it, capability is a commodity everyone can buy, and the entire spread between winners and losers is explained by the judgment curve. We are now to the right of the crossover for most enterprise use cases. That is the single most important fact about your AI strategy, and it is the reason the word "AI-native" is so often misused.
Being AI-native does not mean using the most AI. A company that pours frontier models into every workflow it can find is not AI-native; it is capability-maximizing, and it is competing on the curve that is going to zero. Being AI-native means organizing the whole company around the curve that is going up — treating judgment as the scarce resource and engineering for it deliberately. Less capability, applied with more judgment, beats more capability applied with less. The shovel-sellers win the gold rush. The disciplined win the decade after.
The AI-native question is not "where can we use AI." It is "where is using AI the right call — and where is it the expensive wrong one."
Judgment is not a personality trait. It is a stack.
The trouble with "judgment" is that it sounds like something you either have or you don't — a quality of brilliant executives, unteachable and unsystematizable. That is wrong, and the wrongness is expensive. In enterprise AI, judgment is structured. It resolves into four specific decisions, each of which a team makes whether or not they realize they are making it. Get them explicit and you can get them right. Leave them implicit and you inherit whatever the loudest demo decided for you.
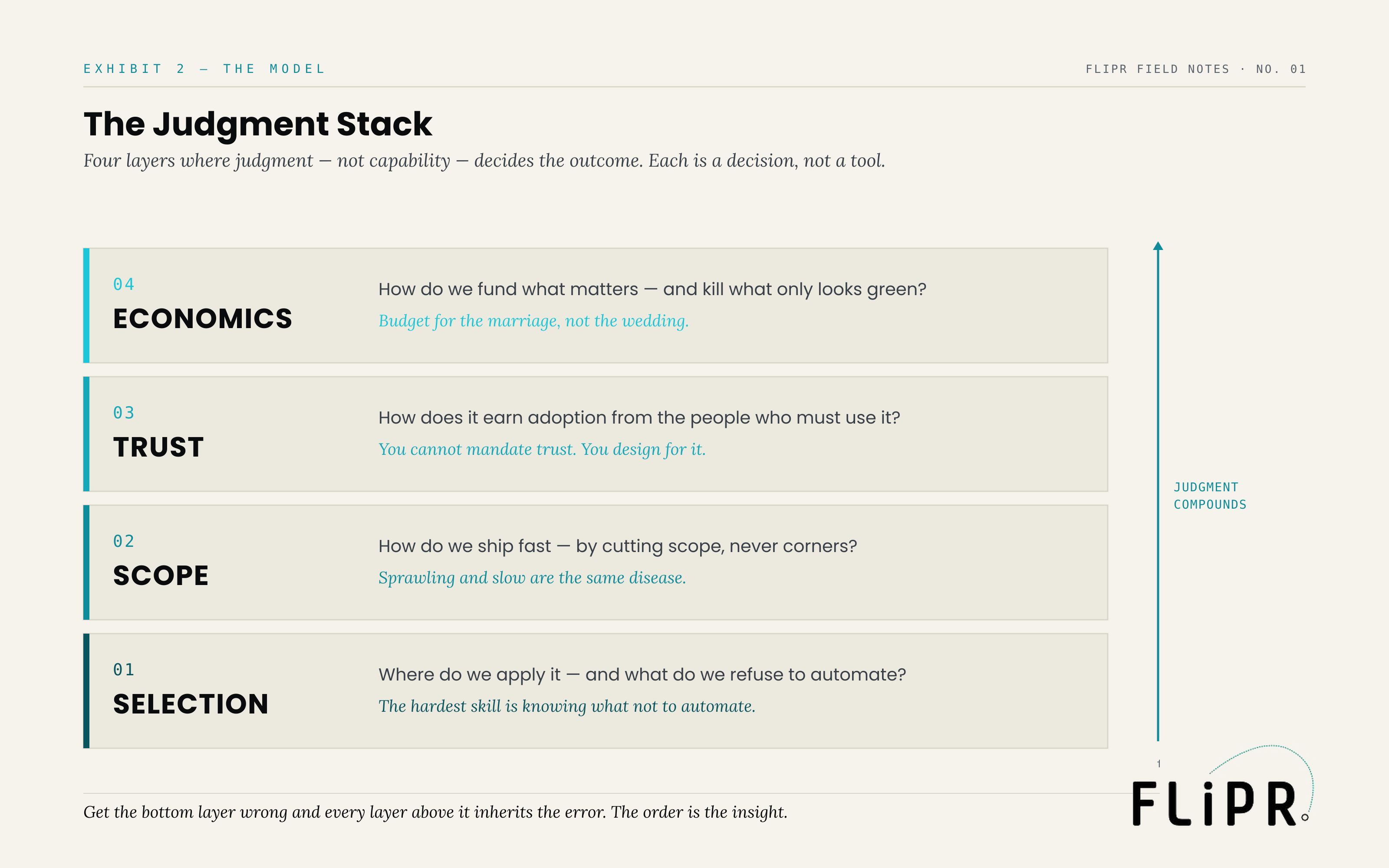 Exhibit 2. Each layer is a decision, not a tool; errors in the foundation propagate upward. The order is the insight.
Exhibit 2. Each layer is a decision, not a tool; errors in the foundation propagate upward. The order is the insight.
Layer one is Selection: where you apply it, and what you refuse to automate. This is the foundation, and the hardest skill in the stack is the negative one — knowing what not to automate. Some decisions carry tail risk, require accountability, or depend on context the model cannot see, and automating them does not save cost; it relocates risk to the worst possible place and removes the human who would have caught it. The discipline is to automate the highest-leverage task a human is genuinely glad to hand over, and to draw a hard line around the ones that must stay human by design. Get this layer wrong and nothing above it can save the project, because you have aimed expensive capability at the wrong target.
Layer two is Scope: how you ship fast — by cutting scope, not corners. Sprawling and slow are the same disease. The instinct under pressure is to broaden — ship everything in the demo, cover every case, look ambitious to the steering committee. It is exactly backwards. Speed comes from shipping one workflow end-to-end and cutting scope to protect the date, not from cutting the testing, the evaluation, or the guardrails to cram more in. A narrow system that works in production beats a broad one that impresses in a review and breaks on contact with a real user.
Layer three is Trust: how the system earns adoption from the people who must use it. You cannot mandate trust. You can mandate logins and then mistake them for adoption, which is how a great deal of "deployed" AI quietly dies. The people best positioned to judge an AI tool's output are usually your most experienced people, and when they resist a new system they are often right — they can see the failure modes leadership's demo did not. Trust is designed, not decreed: show the sources, expose the uncertainty, make failure graceful and visible, and let the expert override the machine. Calibrated trust is a feature you build, not a memo you send.
Layer four is Economics: how you fund what matters and stop what doesn't. Most AI business cases budget the build and forget the marriage. The real cost of an AI system is its total cost of ownership — inference at scale, evaluation, monitoring, retraining, human review, the long tail of maintenance — not the price of getting to launch. And the most dangerous project is not the one that fails loudly; it is the one that succeeds at the wrong thing. Nobody kills a green project. A system can hit every milestone, light up every dashboard, and deliver no economic value — and because it looks green, it runs for years. Economic clarity means modeling the whole lifetime cost and being willing to stop a project that is technically succeeding and strategically pointless.
The last two layers — Trust and Economics — are where this strategic frame meets the delivery floor, and they reappear, in operational detail, as gates in the companion piece on why pilots never reach production. Here they are decisions a leadership team makes about the company. There they are checkpoints a delivery team runs on a live build.
The layers compound, and they compound upward from Selection. An error in the foundation propagates: automate the wrong decision and no amount of trust-building or cost-modeling redeems it. This is why judgment is a stack and not a checklist. The order is the insight.
A pattern we see repeatedly in our own engineering work is worth stating plainly, because it cuts against the intuition: the hardest, most contested conversations in an AI build are almost never about the model. They are about Selection and Scope — what to leave out, and what to refuse to automate. By the time a team is arguing about which model or which framework, the expensive decisions have usually already been made, silently, by whoever framed the pilot. The teams that ship treat the framing as the work. The teams that stall treat it as a formality and spend their energy on the layer that was always going to be a commodity.
What this looks like on Monday
Picture two teams inside the same company — same model access, same budget, same quarter. (This is an illustration, not an account of any specific engagement.)
 Exhibit 3. Same capability, different judgment — and only the judgment shows up in the result. Illustrative, not a client account.
Exhibit 3. Same capability, different judgment — and only the judgment shows up in the result. Illustrative, not a client account.
The first team does what gets applause. They pick the most visible workflow because it will demo well. They broaden scope to look ambitious, then protect the launch date by trimming the evaluation suite. They mandate the rollout and report rising logins as adoption. They budget the build, celebrate the launch, and stop measuring. Six months later the system is technically live, lightly used, quietly wrong in ways no one is testing for, and costing more per query than anyone modeled. It is green on the dashboard. Nobody kills it.
The second team works the stack. They automate the highest-leverage decision their experts are glad to delegate, and they write down what they will not automate. They ship one workflow end-to-end and cut everything else to hold the date. They expose the model's sources and uncertainty so the experts trust it enough to use it and override it when it is wrong. They model the total cost of ownership before they build, and they agree in advance on the condition under which they will shut it down. Their launch is less impressive. Their result is not.
Same capability. The only variable that moved was judgment, and the judgment is the only thing that showed up in the outcome.
Where this argument fails
The honest version of any thesis includes the cases where it breaks, and this one has real ones.
There are domains where capability genuinely is the edge. If you are doing frontier research, a raw capability lead is the whole game until someone catches up. If you operate at extreme scale, a marginal improvement in cost or latency per call compounds into a structural advantage that judgment alone will not match. And in some regulated or safety-critical settings, capability is a binary threshold — the model can either clear the bar the regulator set or it cannot, and no amount of organizational discipline substitutes for crossing it. To the left of the crossover, the capability curve still rules. The argument here is not that capability never matters; it is that for the broad enterprise middle — the place most readers of this actually operate — you are already past the crossover, and you are budgeting as if you weren't.
There is also a cost to the judgment-first stance, and it is not small. Discipline is slower to feel impressive. A capability-maximizing competitor will out-demo you, out-announce you, and look more "innovative" in the quarter you are quietly building something that works. Judgment resists the theater that leadership often rewards — the splashy pilot, the everything-everywhere rollout, the press release. Choosing judgment means choosing to look less busy and be more effective, and that is an organizational and political cost, not just a technical one. If your incentives reward visible activity over durable value, the stack will lose every internal argument until you change the incentives.
That is the steelman, and it bounds the claim rather than breaking it. The exceptions are real and narrow. The rule is broad.
The decision
So here is the decision this should let you make, and it is concrete: stop funding capability theater, and start funding the judgment stack.
Practically, that means three reallocations. Move money off the question of which model — that question is converging to a commodity answer — and onto the four layers: the selection discipline, the scope discipline, the trust design, and the total-cost-of-ownership economics. Change what you reward, so that a team shipping one workflow that works and is used outranks a team launching five that demo well and don't. And put a kill condition on every AI project before it starts, because the most expensive failure mode is the green project that succeeds at the wrong thing and that no one will stop.
The capability will keep getting cheaper. You cannot win on the curve that is racing to zero, and you do not need to. The advantage that is left — the one that is actually getting more valuable as the technology gets more abundant — is the judgment about how to use it. Build the company that has that judgment, and the falling cost of capability becomes the best news you will get all decade: the scarce thing is now the thing you can own.
Sources
- Stanford HAI — Artificial Intelligence Index Report 2025. Falling price-to-performance of frontier-equivalent models; narrowing gap between leading closed and open-weight models. https://aiindex.stanford.edu/report/
- LMArena (Chatbot Arena) public leaderboard. Live ranking spread between leading models, evidence of capability convergence. https://lmarena.ai/
- Gartner. Public projection that the majority of generative AI projects are abandoned after proof of concept. https://www.gartner.com/en/newsroom
- MIT NANDA — The State of AI in Business 2025. Finding that the large majority of enterprise GenAI pilots showed no measurable P&L return.
- Deloitte — State of Generative AI in the Enterprise (2024–2025). Leading barriers to scaling are organizational: data, integration, risk, talent. https://www2.deloitte.com/
- McKinsey — The State of AI (annual survey). Organizational and data-readiness barriers as the primary obstacles to value capture. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
Bottom-line summary (one line)
Capability is commoditizing toward zero, so the durable advantage in enterprise AI is no longer the model — it is the judgment to apply it well, structured as a four-layer stack: Selection, Scope, Trust, Economics.
Suggested LinkedIn hooks (link back to the blog)
- Everyone is asking which AI model to use. It is the wrong question — and the cost curve explains why. The advantage was never the model. [link]
- Forty percent of AI projects fail. Or ninety-five. The numbers disagree, and the disagreement is the most useful thing about them: the projects aren't failing at the model. [link]
- "AI-native" does not mean using the most AI. It means organizing around the one resource that is getting scarcer as capability gets cheaper — judgment. Here is the stack. [link]