Context is the constraint: why what you feed the model matters more than the model
Bottom line: Teams obsess over which model to use and neglect the higher-leverage problem: what information the model actually has in front of it when it answers. A capable model with poor context produces confident nonsense; a modest model with excellent context produces reliable work. Context is not one thing — it is a hierarchy of instructions, knowledge, examples, state, and tools — and most failures blamed on "the model" are failures of one of those layers. The skill that decides output quality for most enterprise work is not model selection. It is context engineering.
You're tuning the model and starving it
Watch how most teams try to improve an AI feature that isn't working well. They compare models, switch from one provider to another, adjust temperature and parameters, and wait for the next, more capable release in the hope it will fix things. The effort goes almost entirely into the model — the one component they did not build and cannot change the fundamental behavior of — while the thing they fully control, the information they put in front of that model, gets a fraction of the attention. The result is a great deal of energy spent on the least tractable lever and very little spent on the most tractable one.
This is a category error about where AI output actually comes from. A language model is a function from context to output: it takes what it can see and produces a continuation. When the output is wrong, the instinct is to blame the function, but far more often the problem is the input — the model was asked to do something with information that was incomplete, unclear, ungrounded, or missing entirely. Swapping the model when the context is starved is like buying a faster car to fix a wrong-directions problem; the vehicle was never the issue. The model is rarely the cheapest lever, and the context almost always is — yet teams reach for the expensive one first.
A language model turns context into output. When the output is bad, look at what you fed it before you blame what produced it.
Context is not the prompt. It's everything the model can see.
Part of the confusion is that "context" gets collapsed into "the prompt" — the immediate instruction typed into the box. But the prompt is only the most visible slice of a much larger thing. Context is the entire body of information available to the model at the moment it generates: the instructions, yes, but also the reference material it has been given, the examples it can pattern-match against, the history of the conversation or task, and the tools and data sources it can reach. All of it shapes the output, and most of it is engineered — assembled deliberately by the system around the model — rather than typed by a user.
This is why "context engineering" has emerged as a distinct discipline from "prompt engineering." Prompt engineering is about wording the instruction well; context engineering is about designing the whole information environment the model operates inside. The latter is a superset of the former, and it is where the leverage is, because most of what determines whether a model succeeds is not how cleverly the instruction is phrased but whether the model has the right knowledge, the right examples, and the right state in front of it. The prompt is one layer. The system that assembles everything around it is the rest.
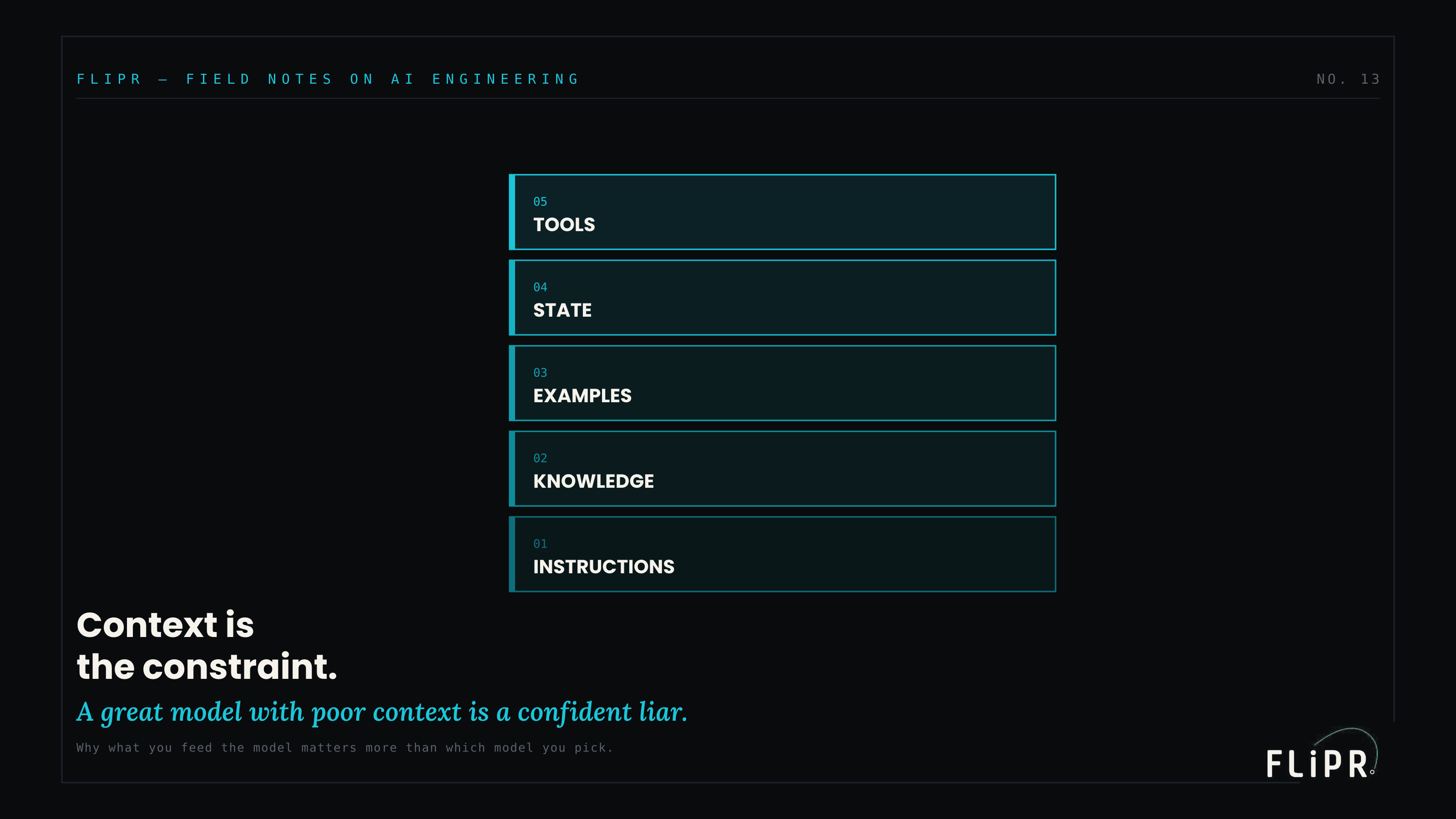
The Context Hierarchy
Context has structure. It is five layers, each supplying something different, each a place to invest.
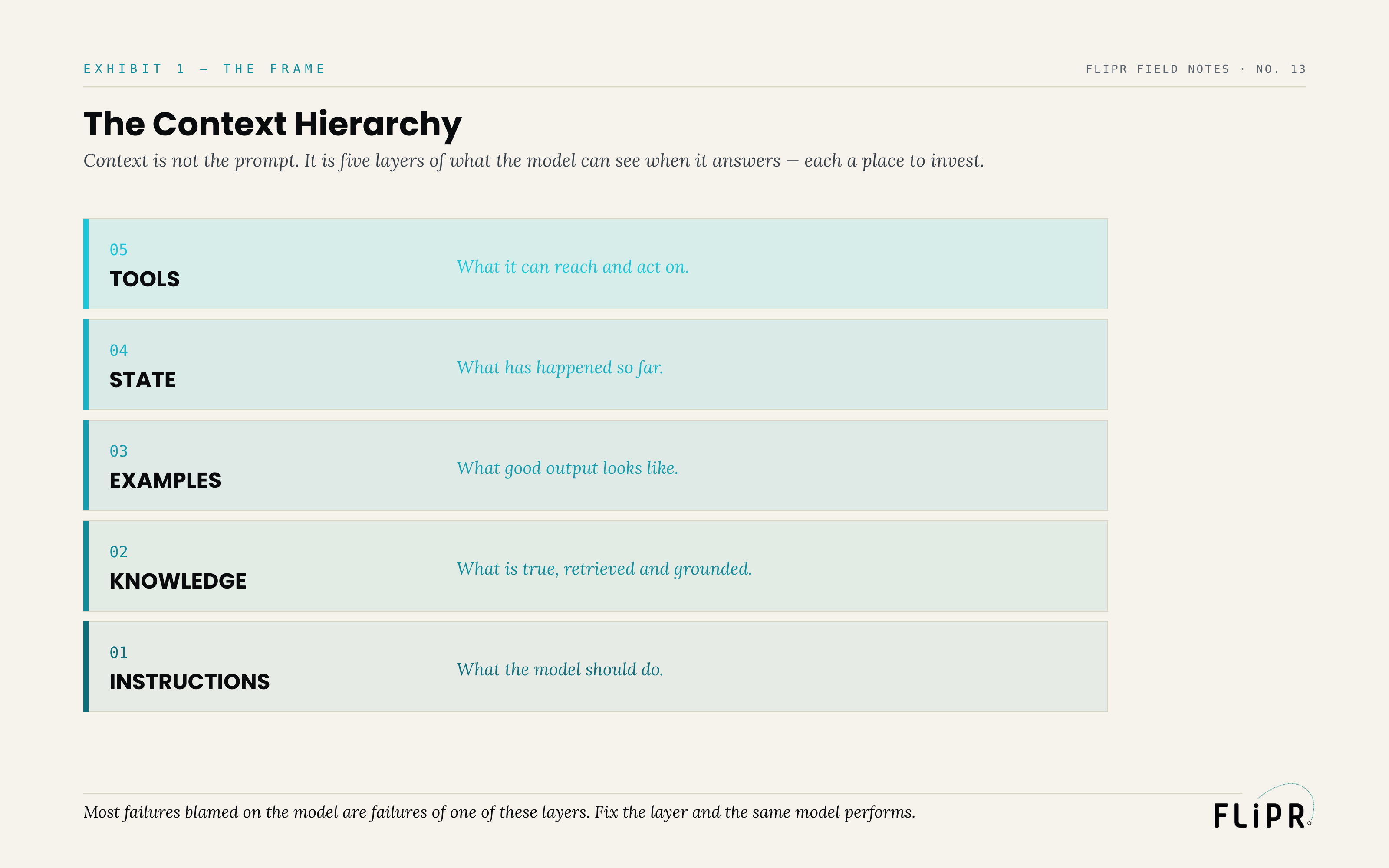 Exhibit 1. Context is not the prompt. It is five layers of what the model can see when it answers — each a place to invest.
Exhibit 1. Context is not the prompt. It is five layers of what the model can see when it answers — each a place to invest.
The foundation is instructions: what the model should do — the task, the constraints, the tone. Above it, knowledge: what is true, the grounded facts retrieved for this specific query rather than left to the model's training memory. Above that, examples: what good output looks like, a few demonstrations that show rather than tell. Above that, state: what has happened so far — the history, the prior steps, what has changed. And at the top, tools: what the model can reach and act on, the systems and data and actions available to it. Each layer answers a different question the model would otherwise have to guess at, and the quality of the output depends on all five, not just the first. A model with perfect instructions but no grounded knowledge will be fluent and wrong; one with knowledge but no examples will be right in substance and inconsistent in form.
The value of seeing context as a hierarchy is diagnostic. When output is poor, the layers tell you where to look — and the answer is almost never "the model is not smart enough." It is that one of these layers was starved, and the fix is to fill that layer, which is cheaper, faster, and more durable than waiting for a better model.
The model is one box. The five layers of context feeding it are five boxes you control — and the output quality lives in those.
Which layer is your failure actually in?
The power of the hierarchy is that each layer fails in a characteristic way, so the symptom points to the layer — and to the fix.
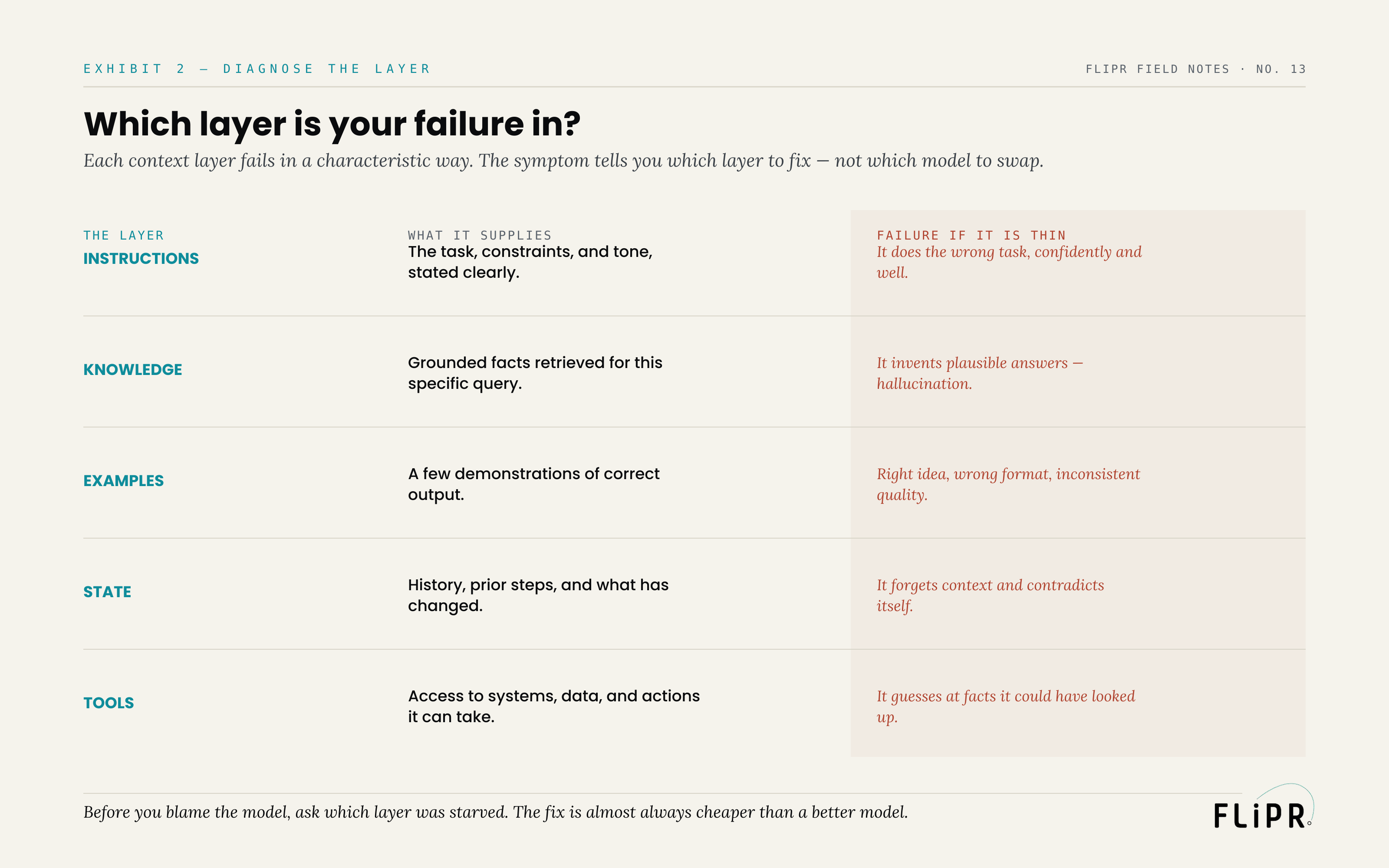 Exhibit 2. Each layer fails in a characteristic way; the symptom tells you which layer to fix, not which model to swap.
Exhibit 2. Each layer fails in a characteristic way; the symptom tells you which layer to fix, not which model to swap.
If the model does the wrong task confidently and well, the instructions layer is thin: it executed clearly, just not what you needed. If it invents plausible but false answers — the failure everyone calls hallucination — the knowledge layer is thin: it was forced to answer from memory because you gave it nothing grounded to work from. If it has the right idea but the wrong format or inconsistent quality, the examples layer is thin: it did not know what good looked like. If it forgets context and contradicts itself, the state layer is thin: it could not see what had already happened. And if it guesses at facts it could have looked up, the tools layer is thin: it had no way to reach the answer. In every case, the symptom names the starved layer, and the remedy is to fill that layer — not to swap the model that was doing its best with what little it was given.
This reframes debugging an AI system entirely. The question stops being "is this model good enough" and becomes "which layer of context did I fail to supply," which is answerable, cheap to act on, and almost always the real issue. The model is rarely the bottleneck. One of these five layers usually is.
What this looks like on Monday
Picture two teams building the same feature, with the same model available to both. (This is an illustration, not an account of any specific engagement.)
 Exhibit 3. One waits for a bigger model; one engineers better context. Illustrative, not a client account.
Exhibit 3. One waits for a bigger model; one engineers better context. Illustrative, not a client account.
The first team is model-first. Its effort goes into comparing models and tuning parameters. When the output is wrong, it concludes the model is not capable enough, and its upgrade path is to wait for — and pay for — a bigger one. The result is a frontier model still producing unreliable work, because the problem was never the model: it was the thin context the team never invested in, and a bigger model fed the same thin context produces the same unreliable output, just more expensively.
The second team is context-first. Its effort goes into engineering what the model sees before it answers — better retrieval, better examples, better state management. When output is wrong, it asks which context layer was thin and fills it. Its upgrade path is to improve retrieval, examples, and state today, with the model it already has. The result is a modest model producing dependable work, because the team invested in the lever that actually moved the output.
Same model available to both. One team waited for a better model and got unreliable work; the other engineered better context and got reliable work from what it already had.
Where this argument runs out
There are limits to this, and they are worth being precise about.
More context is not automatically better, and the instinct to "stuff everything in" is its own failure mode. Models attend imperfectly to long inputs, and a context bloated with marginally-relevant material can bury the signal and degrade output rather than improve it — relevance matters more than volume, and a smaller, sharper context often beats a larger one. Context also is not free: every token costs money and latency, and an over-engineered context pipeline can make a feature slow and expensive in ways that matter at scale, so the engineering is a balance, not a maximization. And there is a real category of genuinely model-bound problems — tasks at the frontier of reasoning or capability where no amount of context will get an inadequate model there, and the right move is in fact a more capable model. The claim is not that the model never matters; it is that for most enterprise work the model is not where the problem is, and treating it as the first lever wastes the cheaper, more effective ones.
That bounds the argument. Curate context for relevance rather than volume, watch its cost and latency, and reach for a better model when the problem is genuinely capability rather than context. The point is to stop reaching for the model first when the context is where the leverage lives.
The decision
So the practical move, before you next conclude that your AI feature needs a better model, is concrete.
When output is wrong, diagnose the context layer before you touch the model — match the symptom to the starved layer and fill it. Treat context engineering as a first-class discipline with real investment: build the retrieval that grounds the knowledge layer, curate the examples that set the quality bar, manage the state that keeps the model coherent, and wire the tools that let it reach facts instead of guessing. Reserve model upgrades for the problems that are genuinely capability-bound, and prove that they are by ruling out the context layers first. And curate context for relevance, not volume, so you are feeding the model signal rather than burying it.
The model you have is almost certainly more capable than the work it is producing, because the work it is producing is limited by the context you are feeding it, not by the model's ceiling. A great model with poor context is a confident liar, and a modest model with excellent context is a reliable colleague. Invest in the five layers you control, diagnose failures as context failures, and stop waiting for a bigger model to fix a problem that was never the model's. The data that grounds the knowledge layer is the same proprietary exhaust the companion piece on the data moat argues is your durable advantage; and the evals in the piece on evaluation are how you know which context change actually helped.
Sources
- Stanford HAI — Artificial Intelligence Index Report 2025. Convergence of model capability, supporting the argument that the model is decreasingly the differentiator relative to how it is used. https://aiindex.stanford.edu/report/
- McKinsey — The State of AI (annual survey). Data readiness and integration among the determinants of whether AI produces reliable, usable output. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
Bottom-line summary (one line)
Output quality is limited by context, not the model — so treat context as a five-layer hierarchy (instructions, knowledge, examples, state, tools), diagnose failures as a starved layer rather than a weak model, and invest in context engineering before model upgrades.
Suggested LinkedIn hooks (link back to the blog)
- You're tuning the model and starving it. A language model turns context into output — so when the output is bad, look at what you fed it before you blame what produced it. [link]
- A great model with poor context is a confident liar. A modest model with excellent context is a reliable colleague. The leverage is in the context, not the model. [link]
- Hallucination isn't usually a model problem — it's a starved knowledge layer. Each context failure has a tell, and the fix is almost always cheaper than a bigger model. [link]