The real AI moat isn't your model. It's your data exhaust.
Bottom line: The model your AI runs on is a commodity your competitors rent on the same terms you do, so it cannot be your moat. But the popular answer — "your data is the moat" — is mostly wrong too: most data a system produces is worthless exhaust, and hoarding it is a cost, not a strategy. The durable advantage is a narrow, specific kind of data exhaust that compounds and that a rival cannot reconstruct. The discipline is knowing which kind that is, capturing it deliberately, and ignoring the rest.

You are investing heavily in the part of your AI that you rent
Look at where the budget goes on most AI initiatives. It goes to the model — choosing it, calling it, prompting it — and to the features built directly on top. This feels like building a product. It is mostly renting one. The model is converging toward commodity status: the price of reaching a given level of capability has fallen sharply, and the gap between the best model and the tenth-best has narrowed to the point where open-weight systems sit within striking distance of the frontier (Stanford HAI, AI Index Report 2025). Whatever you can call, your competitor can call too, at a similar price, often the same week.
Prompts are no better as a moat. A clever prompt is a configuration of a shared asset; it can be reverse-engineered from your outputs, leaked, or simply re-derived by a competent team in an afternoon. Features built on the raw model are the most exposed of all — the day a rival adopts the same model, your feature is reproducible by definition. None of this spending is wasted in the sense of being useless. It is wasted in the sense that it buys no defensibility. You are paying to stand exactly where everyone else can stand.
When your advantage is something a competitor can rent on the same terms, you do not have an advantage. You have an expense.
A moat is not a feature. It is something a competitor cannot copy by trying harder.
It is worth being precise about what a moat actually is, because the word gets attached to things that do not qualify. A moat is a structural asset that a competitor cannot replicate simply by spending more or working harder — it is protected by something other than your effort. A patent is a moat. A two-sided network is a moat. A brand built over decades is a moat. A feature is not a moat, however good it is, because "build the same feature" is a finite, fundable task for anyone with the same tools.
Most things marketed as "AI features" fail this test on the day they ship. They are impressive, they may even be first — but first is not defended, and impressive is not structural. Apply the test honestly to your own roadmap: for each thing you are building, ask whether a well-funded competitor with the same model could reproduce it by deciding to. If the answer is yes, you are building on rented ground, and the question becomes where the un-rentable ground actually is.
Most of your data is worthless. The moat is a narrow exception.
Here the usual story takes a wrong turn. Having concluded that the model is rented, the standard advice rushes to "so your data is the moat" — and that advice is mostly wrong, in a way that costs real money. Most of the data an AI system produces is genuinely worthless as a moat: server logs, undifferentiated transaction records, telemetry that every competitor's system also generates, data you could buy from a broker, data so generic that it confers no edge on anyone who holds it. Accumulating it is not strategy. It is a storage bill, a governance liability, and a security surface, dressed up as defensibility. "We have a lot of data" is one of the most expensive sentences in enterprise AI, because it is almost always true and almost never relevant.
The reason data-as-a-moat has become a cliché is that the slogan is right and the application is lazy. Data confers durable advantage only when it has three properties at once. It must be proprietary — a by-product only your operation can generate, not something purchasable or replicable. It must be compounding — each unit makes the system measurably better, so the advantage widens with use rather than merely accumulating. And it must be defensible by construction — reconstructing it would require a competitor to first possess your customers, your experts, and your workflow, which is precisely what they lack. Data that fails any one of these is exhaust in the literal sense: waste. The moat is the narrow slice that satisfies all three, and the entire skill is telling that slice apart from the heap and refusing to pay to hoard the rest.
"We have a lot of data" is not a moat. It is usually a storage bill that has been mistaken for a strategy.
The Ownership Ladder
So the question is not "do we have data" but "where does our data sit on a ladder from rented to owned" — because durability rises only as you climb toward the narrow slice that qualifies.
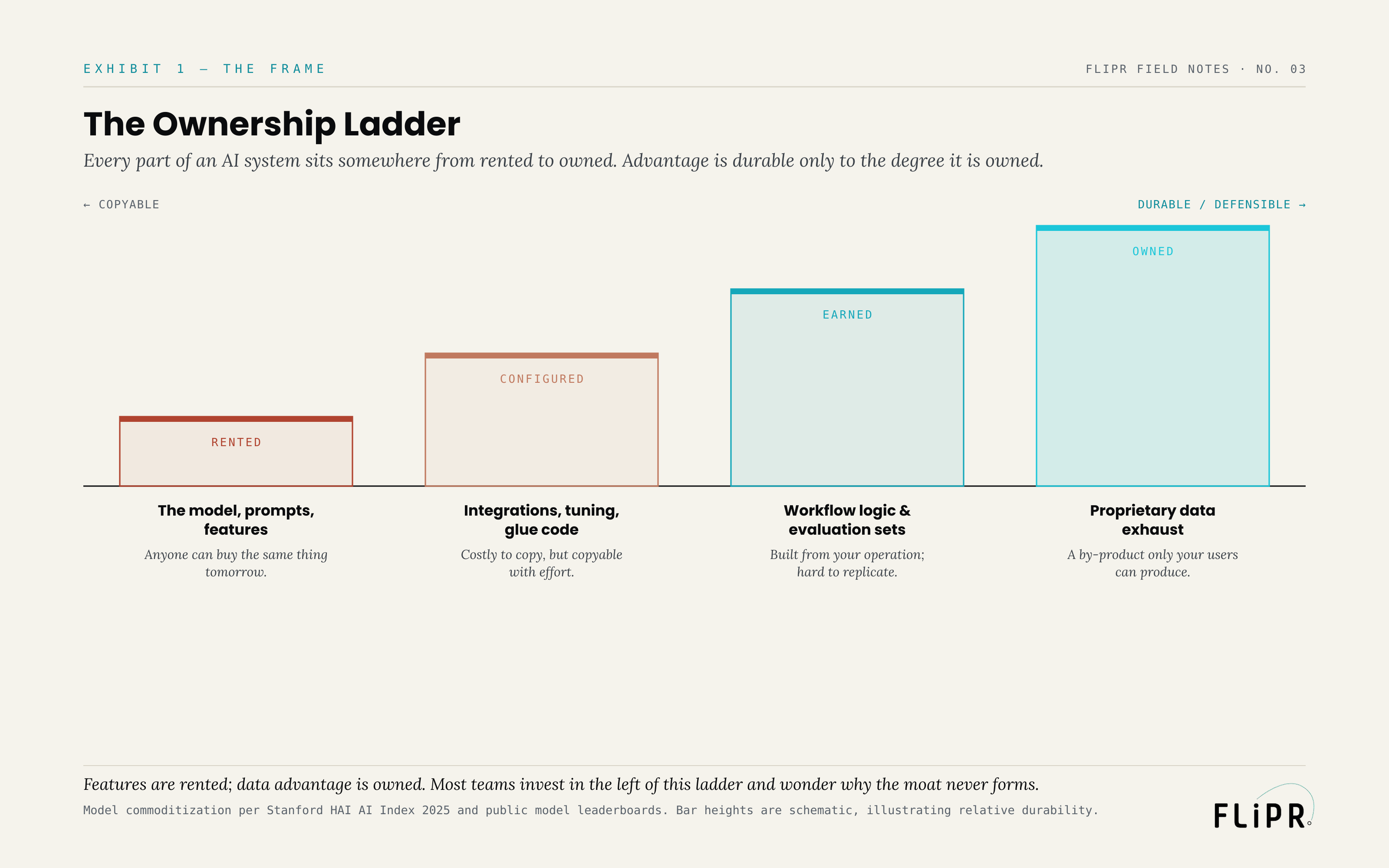 Exhibit 1. Advantage is durable only to the degree it is owned. Features are rented; data advantage is owned.
Exhibit 1. Advantage is durable only to the degree it is owned. Features are rented; data advantage is owned.
At the bottom is the rented rung: the model, the prompts, the features built directly on them. Anyone can acquire the same thing on the same terms. One step up is the configured rung: your integrations, your tuning, the glue code that wires the system into your stack. This is costly for a competitor to copy, but it is copyable with effort — it is engineering, and engineering can be matched. Above that is the earned rung: your workflow logic and your evaluation sets, built out of how your specific organization actually operates. These are hard to replicate because a competitor would have to reconstruct your operation to produce them. And at the top is the owned rung: your proprietary data exhaust — the by-product that only your users, doing their actual work, can generate. It cannot be bought, leaked in a useful form, or re-derived, because it is a record of something only you have: your customers interacting with your system.
The strategic error that this ladder exposes is almost universal. Investment and attention cluster at the bottom — on the rented rung, because that is where the visible product work happens — while the durable advantage sits at the top, largely unbuilt and often actively discarded. Features are rented; data advantage is owned. The teams that build something defensible are the ones that climb.
Data exhaust: the moat you are already producing and probably throwing away
The phrase "data exhaust" matters because it is precise: this is the residue thrown off by your system doing its ordinary job, the way an engine throws off heat. You are producing it right now. The only question is whether you are capturing it.
 Exhibit 2. The narrow data that qualifies: proprietary, compounding, defensible by construction. Most of your data passes none of them.
Exhibit 2. The narrow data that qualifies: proprietary, compounding, defensible by construction. Most of your data passes none of them.
There are four assets worth naming, and what they share is that each passes all three tests — proprietary, compounding, defensible by construction — which is exactly why they are worth capturing when most of what your system emits is not. The first is interaction data — every query, click, correction, and session your users generate. In aggregate it is a behavioral record of how real people use your system for real work, and no competitor can buy or fabricate it because it is specific to your users and your context. The second is expert corrections — the edits your specialists make when they override the model's output. Most systems let those edits vanish into the interface. Captured, they become a labeled training signal tuned precisely to your domain, the most valuable kind of data there is and the kind you cannot purchase. The third is evaluation sets — the real, hard cases you accumulate to test the system before you ship changes safely. A mature eval set is a private benchmark that encodes what "good" means in your context; it is also, not incidentally, the thing that lets you move fast without breaking trust. The fourth is workflow logic — the encoding of how work actually flows through your organization, which is yours by construction because it is a model of you.
None of these can be bought. Each is the residue of your users doing their work, which is exactly the property that makes it un-copyable: a competitor cannot reconstruct it without first having your customers, your experts, and your operation. The exhaust compounds, too. The more the system is used, the more interaction data and corrections accumulate, the sharper the evals get, the better the system performs, the more it is used. That loop is the moat forming. Throwing the exhaust away — returning the output to the user and logging nothing — is throwing the moat away one interaction at a time.
Your competitors can buy the same model. They cannot buy the record of your customers using it. That record is the only thing on the table that is truly yours.
What this looks like on Monday
Take two companies in the same market, starting from the same place, with access to the same model. (This is an illustration, not an account of any specific engagement.)
 Exhibit 3. Same model, same budget — only one strategy leaves a moat behind. Illustrative, not a client account.
Exhibit 3. Same model, same budget — only one strategy leaves a moat behind. Illustrative, not a client account.
The first company treats AI as a feature factory. It ships visible capabilities on top of the model as fast as it can, because features demo well and move the roadmap. Outputs are returned to users and discarded. When its experts override the system, those corrections disappear into the UI. The work is real and the releases are frequent. Eighteen months in, the company has a set of features — every one of which a competitor with the same model now also has, because nothing about them was structural.
The second company ships too, but it instruments the data loop before it ships the feature. Every interaction is captured. Expert corrections are routed into a labeled dataset. Hard cases accumulate into an evaluation suite that gets sharper each quarter. Its releases look similar to the first company's from the outside. But eighteen months in, it is sitting on a data asset its competitor cannot reconstruct — a compounding advantage that grows every time the product is used.
Same model. Same budget. Same number of features shipped. The only difference is that one company kept its exhaust and the other burned it — and only one of them has a moat to show for the year.
Where this argument fails, and what it costs
The honest version of this includes its limits, and the sharpest objection runs against the test itself. The three-property filter is strict by design, and applied too literally it will make you discard data that looks generic today but compounds later — raw interaction logs that seem worthless until a new model architecture can suddenly learn from them, or a corpus whose value only appears at a scale you have not reached. Defensibility is partly a function of what you can do with data, and that changes. So the discipline is not "delete everything that fails the test today," but "invest in capturing and governing the slice that clearly qualifies, and retain the rest cheaply and lawfully without mistaking it for a moat." The error to avoid is the one in the middle: pouring moat-grade investment and moat-grade storytelling into data that is merely accumulating.
Two further limits bound the claim. Even qualifying exhaust is a liability if it is ungoverned — captured interaction and correction data carry privacy, consent, and regulatory obligations, and a pipeline built without governance is a breach waiting to happen; capturing responsibly is real work and the genuine cost of this strategy. And there is a cold-start problem: the loop only compounds once there is usage, so a company pre-traction cannot lean on a moat it has not yet produced. The moat is real, but it is narrow, earned, governed, and slow — not automatic, not free, and not the same thing as "we have a lot of data."
The decision
The decision this leaves you with is concrete.
Run every data asset you hold or could capture through the three-property test — proprietary, compounding, defensible by construction — and sort honestly. Most of it will fail, and that is the point: stop funding, storing as strategy, and telling investors about the data that confers no edge. For the narrow slice that passes, do the opposite of what most teams do — treat it as a first-class product surface. Audit your current AI spend against the ladder, find it concentrated on the rented rung, and move the next dollar up: before you build the next feature, instrument the qualifying exhaust loop it will generate — which interaction data, corrections, and evaluation cases you will capture and govern — and build that capture into the work rather than bolting it on later. Treat the qualifying data loop as the product and the feature as the thing that feeds it.
The model will keep getting cheaper and more capable, and so will your competitors'. You cannot win on the rented rung, and you will not win by hoarding undifferentiated data either. You win on the narrow slice of exhaust that is yours by construction and compounds with use — the record of your own customers and experts doing work only they can do. Build the company that can tell that slice from the heap, capture and govern it, and ignore the rest, and you are building the one thing in your AI stack that is genuinely defensible. This is the durable-advantage answer to the broader shift covered in the companion piece on capability and judgment: as capability commoditizes, ownership of the right data is where the defensibility migrates.
Sources
- Stanford HAI — Artificial Intelligence Index Report 2025. Falling price-to-performance of frontier-equivalent models; narrowing gap between leading closed and open-weight models. https://aiindex.stanford.edu/report/
- LMArena (Chatbot Arena) public leaderboard. Live ranking spread between leading models, evidence of capability convergence. https://lmarena.ai/
- McKinsey — The State of AI (annual survey). Proprietary data and data readiness among the factors most associated with value capture from AI. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
- Deloitte — State of Generative AI in the Enterprise (2024–2025). Data quality, governance, and integration as leading determinants of whether AI scales. https://www2.deloitte.com/
Bottom-line summary (one line)
The model is rented and the moat is owned — durable AI advantage lives in the data exhaust your system already produces (interaction data, expert corrections, evaluation sets, workflow logic), and the teams that win are the ones that capture and govern it instead of shipping features anyone can copy.
Suggested LinkedIn hooks (link back to the blog)
- Your competitors can rent the exact model you use, on the same terms, often the same week. So it cannot be your moat. Here is where durable AI advantage actually lives. [link]
- Most "AI features" stop being an advantage the day a rival ships the same model. A moat is something a competitor cannot copy by trying harder — and you are probably throwing yours away. [link]
- The moat isn't the model. It's the data exhaust: the record of your users doing their work, which no one else can buy or fake. Most teams burn it one interaction at a time. [link]